





























Lösungen

Märkte
Referenzen
News / Events
Terminkalender
Aktuelles
eMagazin
Newsletter
Services
Unternehmen
Profil
Karriere
Partner
Presse
Kontakt

11. August 2019
How to calculate the Azure SQL DTU demand of your on prem database
One of the options to scale Azure SQL Databases is by DTU, database transaction unit (to get an overview and comparison of the purchasing models, check https://docs.microsoft.com/en-us/azure/sql-database/sql-database-purchase-models). But how do you know, how many of those DTUs you need for your on-prem workload? A very helpful tool for that is Azure SQL DTU Calculator, oftentimes wrongly attributed to Microsoft, while in fact it was created and is maintained by Justin Henriksen. By grabbing a couple of performance metrics and uploading the results, you can let it calculate the necessary DTU level for every data point and also present you with a recommendation and a couple of nice graphs. While that is already very good, you might want to do this repeatedly after capturing longer periods of SQL load or on multiple machines and you might want to do your own analysis on the base data. To achieve that, I have created a couple of scripts with the help of my colleagues Christoph Litters and Pascal Poletto.
The TL;DR
You can find the code here in the Axians code sharing platform. It works in four steps:
- Assuming that you have multiple .csv files generated by the scripts shared on the Azure SQL DTU Calculator homepage, the first script accumulates them into one big .csv
- With the second script you convert the .csv file to the .json format expected by the API provided by the calculator and also split it into chunks of 50.000 lines as the API has problems with large files
- The third script calls the API
- The last script interprets the results and gives you a short result overview: the recommended Azure SQL service tiers, the count how often they were recommended, the current price per hour in USD (read via a call to the same backend as the Azure pricing calculator1, the included and the max DB size in GB
The result, imported into Excel looks like this, with the percentage and cost per month easily calculated in Excel
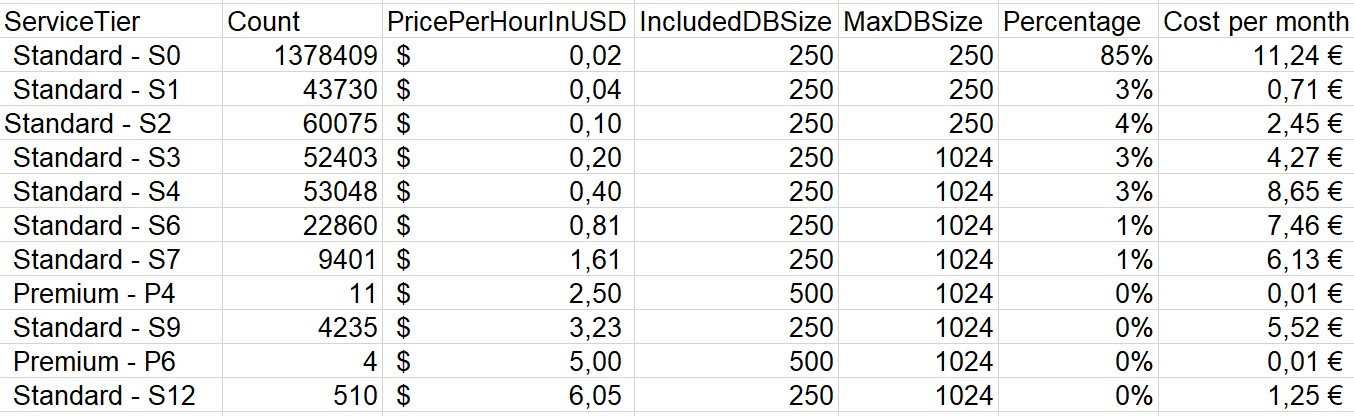
With that you can do your own calculations depending on your needs
The details
The scripts actually are pretty straight forward, so only a couple of things to note:
- As we2 found out when running this on multiple machines over two weeks, depending on your setup and especially localization, the performance monitoring results might look different. Because of that, I am changing the CSV header line to something hard coded in the first script, to make it reliably always the same in order to easily use it in later stages.
- I am not sure if 50.000 lines is the perfect amount of data to send to the API as I have seen larger requests go through as well. It seems like a fair amount with not too many calls and still reasonable response times by the API.
- The scripts are really not complicated, it would be easy to just put everything into one script. But if you run it with more data (we had up to two weeks of performance monitoring data), it can be quite convenient to split it up, so you can easily start at one of the later steps if something went wrong and you don’t want to go through the earlier steps again
- We always deal with database bigger than 2.5GB, which means we can’t use the basic tier. Therefore I have replaced basic with Standard – S0, but if you deal with small databases, you would want to undo this.
- thanks to Pascal Poletto for sharing his scripts for that!
- especially Christoph Litters, as always thanks a lot for your help!
RSS Feed
Kontakt
Kontakt
